MLflow Recipesを調べてみた所感
先日、Databricks社のセミナーを聴講させていただきました。 DataOpsやMLOps, DevOpsという言葉も使われており、データに関することはなんでもサポートしてくれるサービスを目指すという世界観が良いなと思いました。
ここで、MLflow2.0の機能説明もありました。 Databricksで開発を行うと、基本的にMLflowの機能がすぐに使用できるようになっているため、説明があったのだと思います。
その中でMLflow Recipesという機能の発表がありました。 一見便利そうな機能ではあったのですが、時間が限られたセミナーということもあり、具体的にどんなことができるのかを理解することができませんでした。
今回は、そんなMLflow Recipesについて、どんなことができるのか、何が嬉しいのかを簡単に調査してみます。
もし内容に間違いがあったり、機能のアップデートがありましたらコメントいただければ幸いです。
- 先にまとめ
- まずは公式発表を読んでみる
- 既存の機械学習パイプラインのテンプレートを使用できる
- テンプレート化されているのでレビューが比較的易しい
- 分類問題用のテンプレートも存在する
- カスタムモデルも可能ではあるが...
- 動画も確認してみる
- 終わりに
- 参考資料
先にまとめ
調査した上での筆者が感想が大部分です。
- MLflow Recipesは、機械学習パイプラインをテンプレートを使って素早く開発できるものである。
- 一般化されたテンプレートを使うだけで、YAMLファイルと機械学習モデル部分のみの開発に注力できる。
- モデル部分にAutoMLを使用できる。
- データの取り込みからデプロイまでのフローを、コマンドを叩くだけで図示することができる。
- 時系列や深層学習を行うには(不可能ではないと思うが)制約が大きそうな印象がある。
以下、このようなまとめに至った調査内容です。 お時間のある方は読んでください。
まずは公式発表を読んでみる
まず全容を掴むために、Databricks社のブログを読みました。 以下、引用になります。
MLflow Recipes enables data scientists to rapidly develop high-quality models and deploy them to production. With MLflow Recipes, you can get started quickly using predefined solution recipes for a variety of ML modeling tasks, iterate faster with the Recipes execution engine, and easily ship robust models to production by delivering modular, reviewable model code and configurations without any refactoring.
要は、「データサイエンティストのモデル開発を加速化します」と言っています。
では具体的に、どのように加速化するのでしょうか。
上記の引用部分から気になったフレーズを以下の文章をピックアップし、読み解いてみることにしました。
using predefined solution recipes for a variety of ML modeling tasks
reviewable model code and configurations without any refactoring
including support for classification models
既存の機械学習パイプラインのテンプレートを使用できる
1. using predefined solution recipes for a variety of ML modeling tasks
一般的な回帰問題に対応するテンプレートをコピーして、機械学習パイプラインの開発を行うことができます。テンプレートはデータの取り込み、加工、モデル学習、デプロイまでをサポートしています。 これがMLflow Recipesの一番の推しポイントみたいです。
テンプレートは下図の構成になっています。一般的な回帰問題であれば以下の構成で十分だと考えます。

テンプレートのリポジトリはこちらです。これをコピーして開発することになります。
これは特にPoCと本開発のギャップを埋めるのに大きく効果があると思います。
PoCのフェーズにおいては、モデリングを中心にスピード重視の開発になります。 ただスピードを重視しすぎて、本開発や運用を無視したコーディングを行うと、いざ本開発に差し掛かった際に大規模なリファクタリングが必要となります。
MLflow Recipes のテンプレートを使用すれば、PoCフェーズから運用を見据えたコード構成の中で開発を行うことができます。これを「データサイエンティストのモデル開発を加速化します」と表現しているのかなと考えます。
テンプレート化されているのでレビューが比較的易しい
2. reviewable model code and configurations without any refactoring
テンプレートを使用することができるので、実装者に依存したファイルやコード構成を抑制する効果がありそうです。
主に編集するのは、以下の画像のように、FIXMEと記入されている部分です。

テンプレートで既に大まかなパイプラインの構造ができているので、実装者もレビュワー間の想定にミスマッチなども起こりにくいです。結果的にレビューのし易さに繋がるのではないかと考えます。
分類問題用のテンプレートも存在する
3. including support for classification models
これまでは主に回帰問題におけるテンプレートを軸に記述してきましたが、同様のことが分類問題でもサポートされているようです。
カスタムモデルも可能ではあるが...
Databricks社のブログには言及がなかった部分ですが、調べていて気になったのがモデルの部分です。
ドキュメントなどでは、AutoMLやLight GBMなどが主に使用されていました。多くのMLタスクにこれで対応することができます。
一方で、プロジェクトによっては深層学習や時系列、複数モデルのアンサンブルなどを使用したい場合もあります。 その場合にはユーザーがモデルをカスタマイズすることもできます。
しかし、カスタマイズする場合には、以下の引用のように、scikit-learnと同じような構造でないといけないようです。
Returns an unfitted estimator that defines
fit()andpredict()methods. The estimator's input and output signatures should be compatible with scikit-learn estimators.
挙動をしっかり確認したわけではないので憶測でしか話せませんが、時系列や深層学習などをscikit-learn風に寄せて実装することは可能ではあると思います。しかし、実装構成をどうしても強引に寄せていくことには避けられず、かえって労力が必要になりそうな印象です。自分たちでゼロから開発した方が結果的に楽なのではという感想を持ちました。
動画も確認してみる
最後に動画を軽く観てみます。
Databricksで使うことを前提とした機能かもしれませんが、パイプライン全体像の図や、特徴量の分布などをGUI上で確認をしているシーンがありました。エラーや精度悪化に素早く対処したい場合に大きな効果がありそうです。
終わりに
今回はMLflow Recipesの機能について調べてみました。 テンプレートのおかげでデータサイエンティストが運用を見据えた開発を素早く行うことができます。
機会があれば実際に動かして、挙動を確認してみたいです。
参考資料
画像なども以下の記事から拝借しております。本文中に貼ったURLなども再掲しています。
【SQL】not in などでNULLまで抜け落ちる理由を言葉で考える
ご存知の方にとっては常識かもしれませんが、SQLではnot inで条件を指定すると、NULLのレコードも一緒に抜け落ちてしまいます。
実はこの理由がよく分かっていなかったのですが、コードを言葉に置き換えて考えたら納得できたのでメモします。
SQLは<>やnot inでNULLも除かれてしまう
例えば次のような、生徒名と出身都市名のテーブルHometownがあったとします。
| student | city |
|---|---|
| Ken | Tokyo |
| Yui | Fukuoka |
| Ayaka | Tsukuba |
| Koki | NULL |
| Mugi | Sendai |
このテーブルで「Fukuoka, Sendai以外の都市出身の生徒を抽出したい」場合、クエリはこんな感じに書けます。
select student , city from Hometown where city not in ('Fukuoka', 'Sendai')
しかしこの答えからは、Fukuoka, Sendai出身の生徒以外に、出身地がNULLの生徒まで除去されてしまいます。
| student | city |
|---|---|
| Ken | Tokyo |
| Ayaka | Tsukuba |
対応策はnot exists ~を使うことみたいです。詳細は、他の記事に譲りたいと思います。
では、なぜNULLのレコードが抽出されなかったのでしょうか。
除かれる理由は「分からない」から
先ほどの例だとFukuoka, Sendai以外のcity出身者はTrueとなる条件ですが、残念ながらNULLのレコードも抽出されませんでした。
-- 元のコード NULL not in ('Fukuoka', 'Sendai') -- -> False
ここで、NULLは「分からない」値ということを思い出します。
値は「分からない」なので、そこに入るのは、もしかしたらFukuokaかもしれないし、もしかしたらTokyoかもしれないです。
ここで言えるのは、値が「分からない」がゆえにTrueかFalseか断定できない、つまりどちらでもないという事です。
どちらでもないので、inの条件にもnot inにも当てはまりません。
これが、NULLがinにもnot inにも含まれない理由だと理解しました。
参考
考え方は以下の本に載っていました。
VSCode上に文章校正環境をすぐ作成できるようにした話
ブログや職務経歴書など、Markdownで文章を書く際に文章を校正してくれる環境を作成しました。 校正はtextlintで行っています。 VSCode上で動かすことを前提に作っています。
やっていることはtextlintなど、様々な先人たちの知恵をDockerfileなどにまとめて、VSCodeですぐに試せるようにしました、というだけです。 しかし意外なことに、これらをまとめて1つの環境にしている方は意外といなかったので、今回公開することにしました。 もしすでにいたらすいません、その場合は二番煎じです。
できること
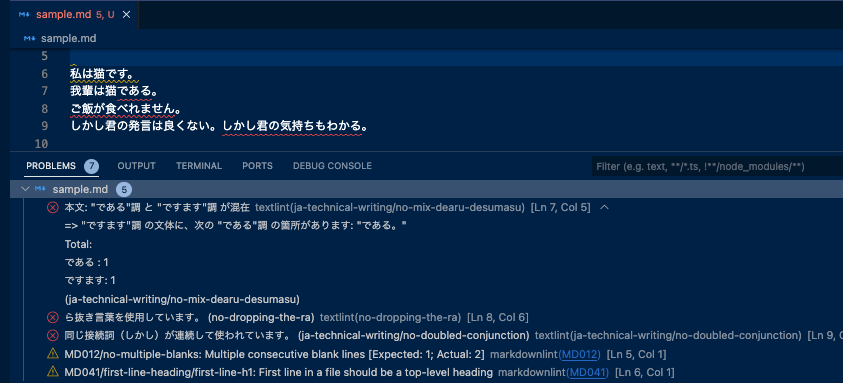
VSCode上で文章を書きながら、自動で校正までやってくれます。 上図では試しにデタラメな文章を書いてみましたが、接続詞の繰り返しや、ら抜き言葉をしっかりと検知できていることが分かります。
VSCodeの拡張機能として静的な解析ツールや、PDF化できるツールも入れてあります。 またgitもコンテナー内で使用できるようにしてあるので、書いたものをgit管理したい方もすぐに使えます。
手順
以下の手順は2022/10/02現在のものです。
- VSCode, Git, Docker Desktopをダウンロードしておく。
- Gitのユーザー名とEmailアドレスを設定する。これを飛ばすとコンテナー内からGithubにpushなどができないか、一手間必要になるかもしれません。参考 逆に、Gitの機能が不要な方はスキップして構いません。
- このリポジトリをforkする。
- forkしたリポジトリをcloneする。
- cloneしたフォルダをVSCodeで開く。参考
- VSCodeの拡張機能Dev Containersをインストールする。
- Ctrl (command) + Shift + P を入力、
Remote-Containers: Reopen in Containerを選択する。 - コンテナーが立ち上がったら、執筆作業を開始できます。
(おまけ)なぜVSCodeにこだわっているか
textlintとDockerを使って1つの環境を用意されている方は何名かいました。
しかし私が作成したリポジトリには、あえてVSCodeしか使えないようなファイルがあります。 これには理由があって、文章校正を「書きながら」注意するレベルで行って欲しかったからです。 例えば口語体での会話や、ネットスラングのような崩した表現をそのまま書きたい場面を想定します。 この時、CIで自動修正されるようにしてしまうと、あえて崩した書き方をしている部分も修正されてしまう恐れがあります。 例えtextlintのルールには反していても、書き手が納得していればOKという使い方もできるように、VSCodeとtextlintのextensionを採用しています。
終わりに
今回Dockerを使った環境構築に初めて自力で挑戦してみました。 奥が深い技術で、正直使いこなせていない感は否めませんが、最低限調べながら実装できるレベルにはなれたのかなと感じてます。
参考(登場していないもの)
Mac USキーボードの日本語/英語切り替え方法を色々試した結果
概要
USキーボードにして唯一困っていたことが、日本語/英語の入力ソース切り替えをどのように行うかです。
色々試行錯誤して、今のところWindows風なキーで切り替えるところに落ち着きました。
今回は、その試行錯誤の過程を共有したいと思います。
同じような悩みを持つ方の助けになれば幸いです。
CapsLockキーで切り替え:不採用
システム設定で下図のような項目をチェックすると、Caps Lockを押すだけで日本語/英語切り替えがスムーズにできます。
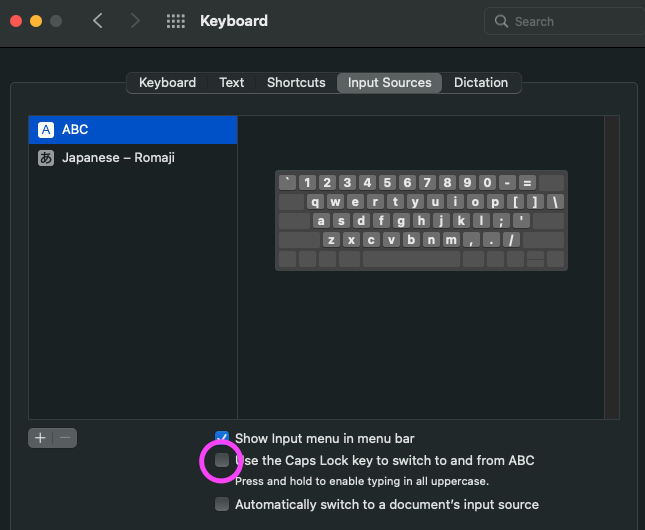
ただ結構な頻度でCaps LockそのものもOnになってしまい、ひたすら大文字が入力されることに…。
特に焦って切り返した時に限ってOnになってしまい、イライラしたので不採用です。
Ctrl + Space で切り替え:しばらく使ってたが不採用
Macのデフォルト設定。結構やりやすさを感じていました。
しかしある日、VScodeをはじめとする主要エディタではCtrl + Spaceでコード補完機能があることをシャの先輩に言われました。知ったかぶりをしながらCtrl + Spaceは入力ソース切り替えで使うのをやめようと決意しました。
Karabinerでカスタマイズする:不採用
外部アプリはあまり入れたくなかったのですが、一旦使ってみました。
まず試したのはJISキーボードMacに寄せるように、左右のCommandキーにそれぞれ日本語変換/英語変換を割り当てる方法です。
この方法は外付けキーボードに右Commandに相当するキーが存在しなかったため断念しました。
他にも色々試しましたが、何かを割り当てるとその代わりに別のショートカットが使えなくなるのが、なんとなく嫌だったので断念しました。
Windows風に切り替え:採用
元々Ctrl + Space でやっていることを他のコマンドに変えるだけです。
System Preferences > Keyboard > Shortcuts > Input Sources で下図の画面に辿り着けると思います(Montereyの場合)。
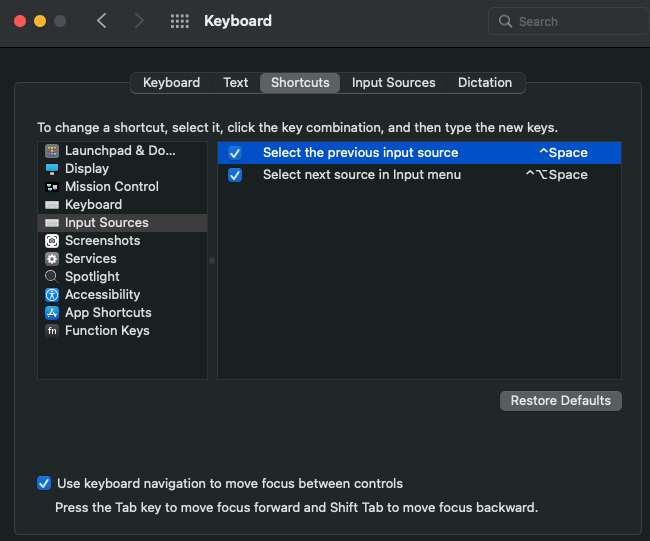
この ^Spaceをクリックすると、何やらキーを変更できそうな雰囲気が出てきます。
その状態でお好みのキーの組み合わせを押すと、新しいキーで日本語/英語の入力ソース切り替えを行うことができます。
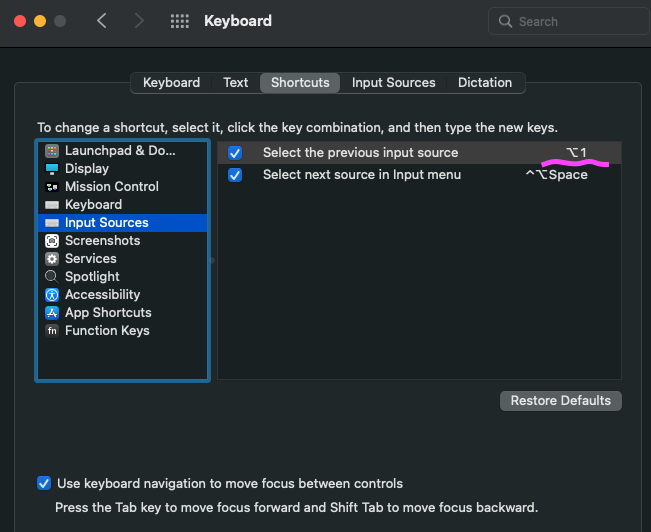
私はWindows風にしたい&MacからWindowsのシンクライアントに接続する機会があるので Option + 1 というキーで切り替えすることにしました。
※Windowsは Option + ` です。
【T-SQL】カスタムエラーで誤ったProcedure実行を止めたい
業務で必要になって調査したら意外と使えそうだったのでメモ。
Procedure内でカスタムエラーを実装して、問題ない場合のみ実行させたくなりました。 ここで言う「問題ない場合」とは以下の2つがあると思います。
- パラメータにTypoがない
- 使用するテーブルに不具合がない(データ連携が遅れていない、欠損がない)
この2つの項目を満たせないままProcedureを実行すると、思わぬ事故につながる可能性があります。
例として、カスタムエラーでProcedure実行を止められないとどうなるか考えてみましょう。
deleteとinsertを行うProcedureを仮定します。
もしdeleteしてしまった後に、insertで失敗していたとします。
すると、deleteは実行されているにも関わらず、insertは実行されていない、いわゆるデータ不整合が発生する可能性があります。
特にこの不具合をユーザーが把握できていないと最悪で、知らぬ間にその後の分析に悪影響を及ぼします。
思わぬデータ不整合を生まないために、独自に設定したバリデーションなどをカスタムエラーとして実装し、Procedureの実行可否を自動判断させる必要があります。
以下のような構造でSQLを書けば、とりあえずTypoやデータの不具合を検知して、問題なければProcedure実行ということができそうです。
ここでは適当なパラメータやテーブルを元に、tblのとあるレコードをtbl_bk内の別のレコードに洗い替える処理を仮定します。
alter procedure procedure_hoge ( @param1 nvarchar(128) @param2 nvarchar(128) ) begin -- 何事もなければtryで完結する begin try begin transaction; -- 表記揺れやデータ不具合を条件分岐で検知 if (select count(1) from tbl where colA = @param1) = 0 begin -- ここからcatch内に飛ぶ, 内容はエラーとして出力される raiserror('@param1 does not exist in tbl', 16, 1); end delete from tbl where colA = @param1 if (select count(1) from tbl where colA = @param2) > 0 begin raiserror('@param2 already exist in tbl', 16, 2); end else if (select count(1) from tbl_bk where colA = @param2) = 0 begin raiserror('You did a typo at @param2.', 16, 3); end insert into tbl from tbl_bk where tbl_bk.colA = @param2 commit transaction; end try -- error検知したら、こちらに移る。以下コピペでOK。 begin catch -- try内transactionを無かったことにする rollback transaction; declare @errorMessage nvarchar(4000); declare @errorSeverity int; declare @errorState int; select @errorMessage = error_message() , @errorSeverity = error_severity() , @errorState = error_state() ; raiserror (@errorMessage, @errorSeverity, @errorState); end catch end ;
基本的には以下項目を守れば、上記のようなSQLは簡単に実装できると思います。
tryとcatchに分けて、うまくいった時、エラー出た時の2つに分けて記述する。- エラー出た時に元に戻せるように、
transactionを組み込む。deleteのみ orinsertのみ行われるという事故を防ぐことができる。
- エラーの出力は
raiserrorを使う。
raiserrorについてもう少し触れます。
「eが1つ足りなくないか?」と思ったあなた。私も思いましたが、どうやら不足している状態が正しいみたいです。気持ち悪いですね。
それはさておき、raiserrorを使用した部分を再掲します。
raiserror('@param1 does not exist in tbl', 16, 1);
上記のクエリでは3つの項目があります。特別な事情がなければこの3つでよさそうです。
1つ目はメッセージです。この部分がエラーメッセージとして出力されることになります。
2つ目はエラーの重大度を表現するみたいです。こだわりがなければ16=「ユーザーが訂正できるエラー」でよさそうです。詳しくは ドキュメント読んでください。
データベース エンジン エラーの重大度 - SQL Server | Microsoft Docs
3つ目は状態を表現するみたいです。ここは正直どう活用すべきか分かっていません。0から255の整数でとりあえずクエリが動きはするので、それ以上深追いはしてません。
参考文献(本文掲載以外)
RAISERROR (Transact-SQL) - SQL Server | Microsoft Docs
トランザクション処理をさらっとマスターしよう:さらっと覚えるSQL&T-SQL入門(12)(3/3 ページ) - @IT
Azure Data Factoryでのデータ処理結果をSlack通知する
はじめに
本投稿では,Azure Data Factoryのデータ加工処理結果をSlack投稿する方法をまとめます.
と言っても,ここ数週間たまたま業務で触っていくうちに知り得たtipsを書き残すだけなので,機能を最大限活用できていないかもしれない点はご了承ください.
最終的に,以下の画像のようなSlack通知を作成することを目指します.

Azure Data Factoryとは
私の認識を一言で言うと,Azure Data FactoryはELTやETL処理過程をGUI上で実装できる,データ加工のためのサービスです,類似サービスにArgo WorkflowsやGCPのCloud Data Fusionなどがあります.

ref: https://docs.microsoft.com/ja-jp/azure/data-factory/introduction
公式サイトには以下のような説明がありました.
追加のコストなしでメンテナンス不要の 90 を超える組み込みのコネクタを使用して、データ ソースを視覚的に統合できます。直感的な環境でコードなしで ETL および ELT プロセスを簡単に構築することも、独自のコードを書くこともできます。
Data Factory - データ統合サービス | Microsoft Azure
名前にAzureと入っているのでAzure系やMicrosoft系のサービスしか利用できないのかと思いきや,PostgreSQLなどのオンプレミス系やAWSなどの他社クラウドサービスも活用したデータ処理過程も実装できるみたいです.1
パイプラインとアクティビティ - Azure Data Factory & Azure Synapse
Azure Data Factory からSlackに通知させる手順
0. 前提条件
このブログのテーマでもあるので言うまでもないですが,以下の前提条件を満たしている環境を仮定します.
- Azure Data Factoryのインスタンスを作成済み(要はData Factoryを使えればOK)
- SlackのWorkspaceを作成済み(要はSlackが使えればOK)
インスタンス作成は以下の記事が役に立つかと思います.
Azure Data Factory UI を使用して Azure データ ファクトリを作成する - Azure Data Factory
1. SlackのworkspaceにIncoming WebHooksを入れる
以下のURLに飛んでください.
するとIncoming WebHooksのinstall画面が出てくるはずです.

右上に使用したいworkspaceが表示されていることを確認して(sign inしていなければしてください),Add to Slackで追加します.
次に出てくる画面で,Azure Data Factory(でなくても良いですが)から処理結果を通知させたいチャンネルを選択します.

Webhook URLはコピーしてどこかに保存しておきます.

2. Azure Data Factory上でPipelineを作成する
Pipelineを作成すること自体は本題ではないので,今回はSQL DataBaseのサンプルProcedureを実行するという,極めて単純なケースを考えます.2
下図がPipelineの全体像になります.

3. Web機能を使ってSlack通知を実装する
本題です.まず,先ほど作成したPipelineにWebという機能を2つ追加します.何故2つかというと,成功した場合の通知と失敗した場合の2種類が必要になるからです.
作成したらPipelineの最後尾とWebを矢印で繋ぎます.最後尾に緑色の突起があるので,それをドラッグして繋ぎます.下図のようなイメージです.

緑色の矢印はそれまでの実行が成功した場合の矢印を示します.失敗した場合の通知機能NoticeFailureへの矢印は赤色に変更をします.矢印を選択後,右クリックでパターンを変更することができます.

ここまでできたらSlackに通知させる機能を実装していきます.
先ほどのNoticeSuccessを例に中身を見ていくと以下のようになります.映っていない部分は一旦デフォルトのままで特段問題ないと思います.

URLの部分には手順1でメモしてあるはずのwebhook URLを入力してください. なんとなく見れば分かりますが,bodyの部分はそれぞれ次のような要素になっております.
{ “username”: Slackでのユーザー名, “text”:本文, “icon_emoji”:Slackの絵文字 }
NoticeFailureも同様の形式で実装します.これで通知機能は完成です.
4. Test
実際に動作するのか確かめてみましょう.
Azure Data FactoryではDebugというところをクリックすると,パイプラインが実行されるようになっています.
成功時

失敗時

SlackでAzure Data Factoryの実行状況を通知させることができました.
応用例
以上で本題は終了なのですが,ついでに私がこれまでの業務で獲得したいくつかのtipsを紹介します.
トリガーを設定する
上記の例だと手動で単一のProcedureをわざわざGUI上のサービスで実行し,その結果をわざわざSlackで確認するみたいな流れになっていました.スポットでの実行であれば,わざわざAzure Data Factoryを使用する必要がありません.
しかしこのProcedureが1時間に一度,1日に一度というようにバッチ処理させたい場合もあるでしょう.自動でProcedureを実行させ,その結果を自動で通知することができる機能が欲しくなってきます.
このような場合,トリガーを設定すれば自動実行させることが可能となります. またトリガーとSlack通知を組み合わせることで,基本的には自動でPipelineを実行し,問題が発生した場合はそれをSlackから把握し,原因調査やリカバリー作業につなげることができるようになります, こういった状況では通知機能のありがたみが分かりますね.
設定方法を簡単に説明します.Pipeline設定画面から,Add triggerを選択,新規作成をしようとすると以下のような画面が出てきます.こちらは1時間に一度自動でパイプラインが実行されるように設定したものとなります.

トリガーは時間帯,n分に一度という設定方法のほか,ストレージにファイルがアップロードされたら実行が開始されるなどの設定も可能です.
詳しくはドキュメント見てください.
パイプラインの実行とトリガー - Azure Data Factory & Azure Synapse
カスタム絵文字を設定する
通知するアイコンはデフォルトで登録されている絵文字でも問題はないですが,ついでに遊び心もしのばせておきたい時があると思います.
後からユーザーが独自に追加するカスタム絵文字でも問題なく通知に組み込むことができます.
試しにこちらのサイトから画像を拝借し,アイコンの部分だけ変えて通知してみます.

成功通知:「アーニャのおかげ!」って声が聞こえてきそうです

失敗通知:ショックの度合いがひしと伝わってきます3

ここで注意事項なのですが,Slackの絵文字を日本語文字列で入力するとうまくいきません.
例えば,文字列で:やっほー:という絵文字がありますが,これではAzure Data Factoryは読み取ってくれないので,英語での文字列の:hugging_face:と入力する必要があります.
カスタム絵文字の場合は絵文字の名前を日本語で登録しないよう気をつけてください.
話は逸れますが,絵文字以外もカスタマイズして,よりリッチな通知を実装させることも可能です. 以下の記事が参考になるかと思います.
SlackのIncoming Webhooksを使い倒す - Qiita
上記の記事に載っていて大変便利だと感じたのですが,通知画面のUIを見比べながらjsonの実装内容を生成できる優れものもあるみたいです.
https://api.slack.com/docs/messages/builder
詳細な実行結果を取得する
通知内容が「成功した」「失敗した」でも最低限の状況は分かりますが,「成功した」と通知されていても,実は不具合が発生している場合も考えられます.
例えば,平常時なら100レコードほどがInsertされるPipelineで,10レコード程度しかInsertされなかった場合,そのPipelineかその前の段階での不具合を疑う必要があります.
しかしこれまでの「成功した」通知だと,平常時よりも極端に少ないレコード数しかInsertされていることに気がつくことができません. データに不具合があることを見落としてしまうと,後続のダッシュボード可視化や機械学習モデルに正しくないデータを流し込んでしまいます.
ここで,実行時にどのくらいのレコード数がInsertされたのかも併せて通知させれば,極端な実行結果になっていること把握することができます. 即ち予期せぬ不備やエラーが発生しているなどの現象を疑うことが可能になります.例として今回はこれを実装しましょう.
Pipelineの流れとして,こちらを仮定します.
- とあるProcedureを実行する
- テーブルに国ごとにどのくらいのレコードがあるか確認する
- 国ごとのレコード数を通知する
詳細は省力しますが,これを実装すると以下のようなフローになります.
全体像がこちら

ForEachCountryArrayの中身

getCountriesでテーブルにある国のリストを抽出SetCountryArrayでjson形式の結果をArray型に変換してCountryArrayに保持ForEachCountryArrayでCountryArrayを繰り返し処理,即ち要素ごとの処理を実行SetCountryでその繰り返しターンで処理する国名を保持HowManyRecordsで国に該当するレコード数をカウントSetCountで上記結果を変数として保持NoticeSuccessでSlack通知
国ごとにどのくらいのレコードがあるかを通知させるには,ForEachCountryArrayの内部の結果を通知文に掲載した状態にする必要があります.ここが,これまでの固定されたjson形式で記述していた方法とは異なる部分になります.
実行結果などを通知に組み込むためには,NoticeSuccessのbody部分を以下のように記述するのがコツです.
@json( concat( '{"username": "NoticeBot(Success)",', '"icon_emoji": ":anya_good:",', '"text": "', variables('Country'), -- 国を表現する変数 'に関するレコード数は', variables('Count'), -- レコード数を表現する変数 '行です"}' ) )
一旦String型として結合させてから,再度json 形式に修復させるという形をとっています.単純に面倒なのと,”や,の位置など間違えやすいので気をつけてください.私は{を忘れておりしばらく詰まってしまいました.
追記(2022/08/17)
上記のようにconcatで頑張らなくても、Pythonのf-stringのような書き方も可能なようです。
{ "username": "NoticeBot(Success)", "icon_emoji": ":anya_good:", "text": "@{variables('Country')} に関するレコード数は@{variables('Count')}行です" }
Azure Data Factory でパラメーターと式を使用する方法 - Azure Data Factory | Microsoft Docs
これで実行すると次のような通知がSlackに届きます.これで急にレコード数が増加/減少したなどを把握することができるようになりました.
終わりに
今回この記事を作成するにあたって初めてAzureを個人アカウントで使用しました.Pythonの挙動や機械学習についての記事を書く場合は,google colaboratoryなどでサッと実装できたのですが,今回は環境作りに苦労しました.聞き慣れない言葉の並ぶ画面でのサービス登録,データベース準備,触ったことのないデータを使った例題考案…といった部分で,無駄に時間を溶かしてしまいました.
参考(本文中に掲載したものを除く)
- Azure Data FactoryのScript4の実装例が参考になります.
How To Use Script Activity in Azure Data Factory
- サンプルのデータベースを作成する際に参考にしました.
AdventureWorks サンプル データベース - SQL Server
- Pipeline作成の大枠を掴むのであれば以下の記事がおすすめです.
Azure Data Factoryを触ってみる #Azureリレー | cloud.config Tech Blog
- 色々なデータ処理を実装して見たくなったら以下の動画もおすすめです.
ガウス過程で時系列予測する
概要
ガウス過程を活用した時系列モデル(特に予測)ってあまり聞かないなと思い,今回試してみました. 結論から言うと,特徴量を工夫すれば使えないこともないですが,あえてガウス過程を使う理由はなさそうです.
私のガウス過程に対する浅学により,知識のある方からすると「そんなの当たり前だろ」と言われてしまいそうな結論になってしまいましたが,ご笑覧いただければ幸いです.
実行コードはこちらです.
ガウス過程とは
まだまだ筆者も勉強中なので詳しい説明ができなくて恐縮なのですが, 共分散行列などが解法にででくるところから推測するに,同じような特徴量を持つときは同じような目的変数になるだろうみたいな予測をするのだと認識しています.
以下のページが分かりやすかったです.
使用データ
prophetの公式ドキュメントで使用されている以下のデータを使用しました.
wgetが入っている方は以下をjupyterとかで実行すればダウンロードできます.
wget https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_peyton_manning.csv
グラフに可視化すると以下のようになります. 年ごとの動きが似ており,年間の季節性があると考えることができます. なお,ガウス過程が平均0の変動を仮定しているみたいだったので,ダウンロードしたデータを標準化したものを扱うこととします(標準化しなくても良い方法あればご教示ください).
df = pd.read_csv('./example_wp_log_peyton_manning.csv', parse_dates=['ds']) # 2015年以降をテストデータ,それ以外を学習データとする df['is_train'] = df['ds'] < pd.to_datetime('2015-01-01') # ガウス過程は目的変数の平均0を仮定しているようなので,標準化する df['y'] = (df['y'] - df['y'].mean()) / df['y'].std() plt.figure(figsize=(12, 8)) plt.scatter(df['ds'], df['y'], color='#999999', label='y_true') plt.xlabel('ds') plt.grid() plt.legend(loc='upper left') plt.show()

三角関数で季節成分を表現
年次の季節性が確認できたので,ここでもprophetの真似をして 以下のフーリエ級数のような式をN=10まで特徴量として生成します.
ここで,は各三角関数の重みです.
回帰モデルの際は必要ですが,今回はガウス過程なので必要ありません.
またpは1周期の期間です.今回は年次の周期性を表現したいので,
とします.
コードで表現すると以下のようになります.
def add_fourier(df: pd.DataFrame, period: float, order: int) -> pd.DataFrame: df[f'fourier_O{order}_sin'] = np.sin(2 * np.pi * order * np.arange(len(df)) / period) df[f'fourier_O{order}_cos'] = np.cos(2 * np.pi * order * np.arange(len(df)) / period) return df for i in range(10): df = add_fourier(df, period=365.25, order=i+1)
詳しく知りたい方はprophetの論文を読んでみてください.
学習・予測を実行してみる
今回,ガウス過程の計算にはGPyというライブラリを使用します.
カーネルを適当に設定して,とりあえず動くか見てみます. 必要なライブラリをimportします.
import GPy from GPy import kern
カーネルの設計や,学習予測は次のように行うようです.
kernel = kern.RBF(input_dim=20) + kern.Bias(input_dim=20) x_columns = [c for c in df.columns.tolist() if 'fourier' in c] m = GPy.models.GPRegression( X=df.loc[df['is_train']==True, x_columns].values, Y=df.loc[df['is_train']==True, 'y'].values[:, None], normalizer=None ) yhat, yhat_var = m.predict(df.loc[:, x_columns].values) yhat_std = yhat_var ** .5
予測結果を可視化してみましょう.
plt.figure(figsize=(12, 8)) plt.scatter(df['ds'], df['y'], color='#999999', label='y_true', s=10) plt.plot(df['ds'], yhat, label='y_pred', color='#377eb8') plt.fill_between( df['ds'], yhat.reshape(-1) - yhat_std.reshape(-1), yhat.reshape(-1) + yhat_std.reshape(-1), color='#377eb8', alpha=.2, label='1 sigma' ) plt.vlines(pd.to_datetime('2014-12-31'), -4, 5.5, label='End of training', color='k') plt.xlabel('ds') plt.grid(linestyle='--') plt.legend(loc='upper left') plt.show()

予測期間(End of trainingより右側)において,少しスケールが正解値y_trueと予測値y_predで異なってしまっていますが,概ねの形はうまく予測できているのが確認できます.
終わりに
特徴量に無理やり三角関数を導入したあたりで,「それガウス過程でやる意味ある?」という疑問が出てきました. LSTMやProphetのようなモデルで十分そうなことをわざわざ難しくしすぎてしまった感が出てしまいました.
とはいえ,一応ガウス過程でも時系列予測ができそうなことは確認できました.
今後の個人的な課題は,ガウス過程やカーネル法を導入することで何が嬉しいのか勉強することです. 時系列でも使えそうだなということ自体,私の勘違いの部分が大きかったので,この分野は全体的に知識が浅いなと痛感しました.